【问题记录】 requests ChunkedEncodingError IncompleteRead问题的阳间解决方案
0x01 概述
之前用Python处理了一个请求,遇到了如下报错。
requests.exceptions.ChunkedEncodingError: ('Connection broken: IncompleteRead(0 bytes read)', IncompleteRead(0 bytes read))
奇怪的是挂上Burp Suite代理后异常就不见了,莫非遇到了薛定谔的异常?
0x02 问题分析
查了一下这个问题,主要是HTTP分块(chunked)传输的时候出错了,关于HTTP的chunked,可以参考以下链接:
那就先抓个包看一下,Wireshark和Burp Suite一起看。


从这里就能看到异常了,一共发起了两个请求,但是Wireshark里面第二个请求没有响应,但是Burp Suite里能看到完整的两次请求和响应,应该是Wireshark没有正确解析HTTP响应。
这种情况直接Wireshark里看一下TCP流,发现确实是收到了响应。
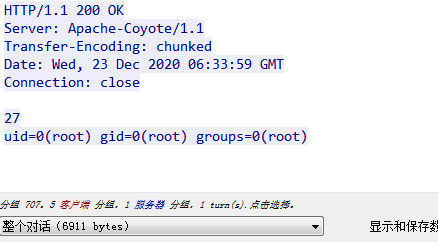
再看一下Burp Suite收到的是什么
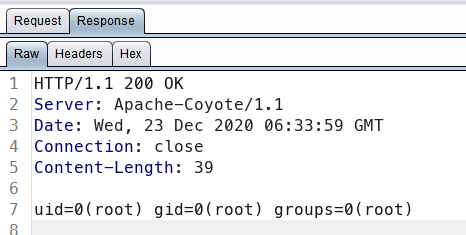
这里就能看出问题了,明明响应是chunked方式传输了,到Burp Suite里却不是分块传输了,其实也好理解,Burp应该是对响应做了解析和处理,这也就解释了为什么挂上Burp代理后就不再报错了。
再看报错原因,回去翻文档看下chunked的描述:
数据以一系列分块的形式进行发送。
Content-Length首部在这种情况下不被发送。。在每一个分块的开头需要添加当前分块的长度,以十六进制的形式表示,后面紧跟着 ‘\r\n’ ,之后是分块本身,后面也是’\r\n’ 。终止块是一个常规的分块,不同之处在于其长度为0。终止块后面是一个挂载(trailer),由一系列(或者为空)的实体消息首部构成。
给的示例长这样:
HTTP/1.1 200 OK
Content-Type: text/plain
Transfer-Encoding: chunked
7
Mozilla
9
Developer
7
Network
0
哦,chunked结束需要有一个0长度块做终止,这里的Wireshark响应里明显没有这个0,导致了Wireshark解析异常,也导致了requests解析异常,但其实这个异常是由requests使用的内置库urllib3抛出的,这个后面再说。
0x03 解决方案
在我查这个问题的时候遇到了下面几种方案:
- 修改requests代码,捕获异常。但是上面说了,这个解析逻辑是内置库urllib3实现的,改内置库太阴间了。
- 改服务器,服务器是你的那就改改吧。
- 捕获异常并pass,这样确实能请求,但是response.text和response.content均是空的
- 用requests的stream参数,但是没用,只是没用该参数的时候是请求即异常,用了stream参数后,解析会在你调用response.text和response.content的时候进行,并在此时引发异常
- 修改请求为HTTP 1.0,这个我就不评论了,效果和3,4差不多,响应体是空的,并且你在代码里改协议版本,是可能对整个外部代码框架造成影响的。
如果不需要获取响应的内容,可以直接捕获异常,如果需要响应内容,需要以下方式读取:
既然解析会出异常,我们就需要获取原始数据,好在requests提供了这个方法,即response.raw,注意使用raw时,必须在请求时将stream参数设置为True。那raw怎么读?官方文档好像没写,直接看定义吧。定义有下面的注释:
#: File-like object representation of response (for advanced usage).
#: Use of ``raw`` requires that ``stream=True`` be set on the request.
懂了,和文件差不多。不过还有个问题,读的时候要用readline()逐行读,直接read如果越界,或直接readlines(),都会导致位置原因的错误,最后读到的结果只有一个描述信息。
最后放个demo:
def demo(url, headers):
contents = []
try:
resp = requests.get(url=url, headers=headers, stream=True)
content = resp.raw.readline()
while content:
contents.append(content)
content = resp.raw.readline()
except Exception:
pass
return b''.join(contents)